
DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement
DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement
Yanxin Hu와 Yun Liu 가 2020년 interspeech에 기재된 논문이다. 논문과 정리한 내용은 아래에서 받을 수 있다. 모델의 구조에 대해서만 간략히 정리한 글이니 related work나 experiments는 요약본을 참고하자.
DCCRN model
DCCRN은 기존에 나온 Convolution recurrent network(CRN)과 Deep complex U-net(DCUNET)을 결합하여 만든 모델이다.
CRN
Convolutional encoder-decoder(CED)는 time-domain approach에서 Conv1d를 통해서 feature를 얻을 때 사용되었는데 CRN은 TF-domain에서 Conv2d CED를 통해서 feature를 얻었다.
CED는 input으로 complex-valued와 real-valued spectrogram을 받을 수 있는데, complex-valued spectrogram은 magnitude와 phase 꼴로 변형될 수도 있고 real과 imaginary 꼴로 CED에 들어갈 수도 있다. 기존에는 phase를 무시하고 magnitude만을 추정한 뒤 noisy speech의 phase와 estimated speech의 magnitude를 통해서 speech를 복원했는데, 해당 방법은 한계가 있고 최근에는 phase까지 추정하는 방법에 대해서 연구가 이루어지고 있다.
Complex spectral mapping with a Convolutional Recurrent Network for Monaural Speech Enhancement와 같은 모델을 보면 magnitude만을 추정할 때보다는 성능향상이 있지만, 두개의 input channel인 real과 imaginary에 공유되는 하나의 convolution filter로 convolution연산을 한다는 한계가 있다.
DCUNET
DCUNET은 deep complex network와 u-net을 결합하여 만들어졌다. 매우 좋은 성능을 보여줬지만 큰 모델사이즈와 연산량때문에 실질적 활용은 어려워보인다.
DCCRN model structure
DCCRN은 CRN보다 성능적으로 우수하며 DCUNET과는 비슷한데 DCUNET보다 연산량이 1/6수준으로 적다. 전반적인 모델 구조는 아래 보이는 것처럼 u-net과 비슷하다.
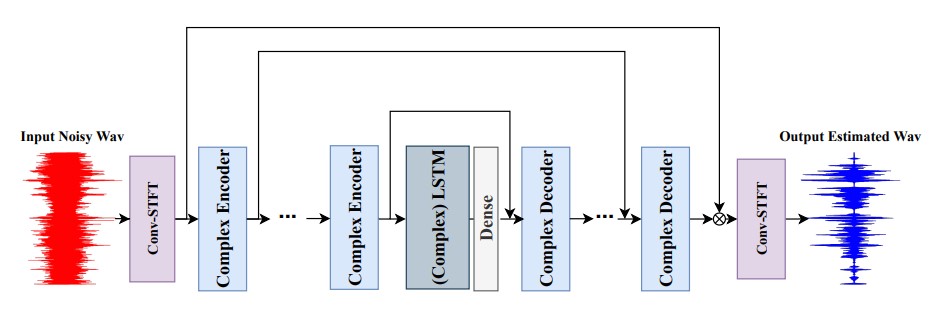
Encoder and decoder with complex network
DCCRN은 CRN의 convolution을 개선하여 DCUNET처럼 complex multiplication을 반영하여 연산한다. Encoder의 경우, convolution kernel을 \(W=W_r+jW_i\), input을 \(X=X_r+jX_i\)라고 하면 다음과 같이 출력한다. \(F_{\text{out}}\)은 하나의 layer마다의 output을 의미한다.
\[F_{\text{out}}=(X_r * W_r - X_i * W_i)+j(X_r * W_i + X_i * W_r)\]Complex LSTM의 real과 imaginary LSTM을 분리하여 각각 \(\text{LSTM}_r\), \(\text{LSTM}_i\)라고 했을 때, complex LSTM의 output은 다음과 같다.
\[F_{rr}=\text{LSTM}_r(X_r)~~F_{ir}=\text{LSTM}_r(X_i)\] \[F_{ri}=\text{LSTM}_i(X_r)~~F_{ii}=\text{LSTM}_i(X_i)\] \[F_{\text{out}}=(F_{rr}-F_{ii})+j(F_{ri}+F_{ir})\]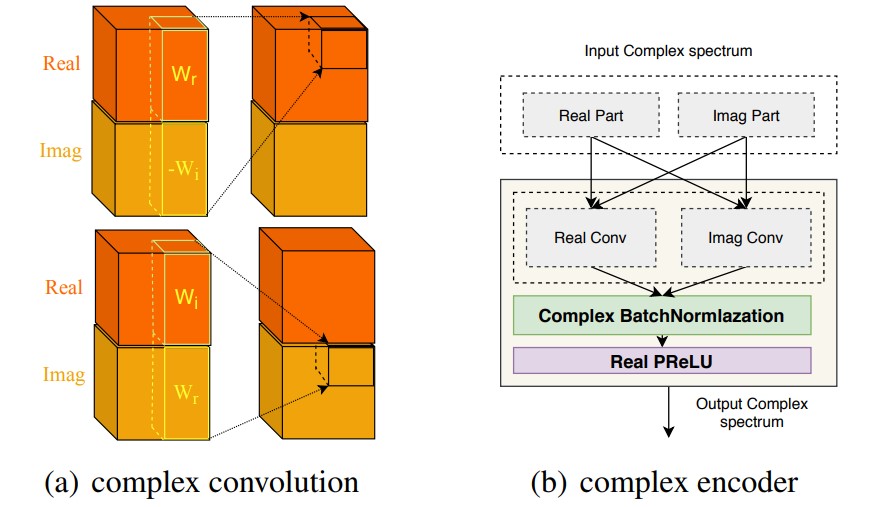
Target
DCCRN은 mask를 추정한다. 추정하는 mask에 따라서 DCCRN의 유형을 분류한다. 추정한 mask를 \(\tilde{M}=\tilde{M}_r+j\tilde{M}_i\)라고 할 때, mask의 polar coordiante form은 다음과 같다.
\[\tilde{M}_{\text{mag}}=\sqrt{\tilde{M}_r^2+\tilde{M}_i^2}\] \[\tilde{M}_{\text{phase}}=\text{arctan2}(\tilde{M}_i,\tilde{M}_r)\]DCCRN은 3가지 종류의 complex ratio mask를 target으로써 추정한다. \(Y=Y_r+jY_i\)가 noisy speech일 때 mask를 통해서 estimated speech를 얻는 방식은 다음과 같다.
\[\text{DCCRN-R}: \tilde{S}=(Y_r\cdot\tilde{M}_r)+j(Y_i\cdot\tilde{M}_i)\] \[\text{DCCRN-C}: \tilde{S}=(Y_r\cdot\tilde{M}_r-Y_i\cdot\tilde{M}_i)+j(Y_r\cdot\tilde{M}_i+Y_i\cdot\tilde{M}_r)\] \[\text{DCCRN-E}: \tilde{S}=Y_{\text{mag}}\cdot\tilde{M}_{\text{mag}}\cdot~e^{Y_{\text{phase}}+\tilde{M}_{\text{phase}}}\]DCCRN-R은 real과 imaginary mask를 각각 씌운 것이고 DCCRN-C와 DCCRN-E는 complex ratio mask(CRM)를 적용한 것이다. 아래의 전개과정에 따라서 둘이 같은 target을 추정한다는 것을 알 수 있다.
\[\text{DCCRN-E}: \tilde{S}=Y_{\text{mag}}\cdot\tilde{M}_{\text{mag}}\cdot~e^{Y_{\text{phase}}+\tilde{M}_{\text{phase}}}\] \[=(Y_{\text{mag}}\cdot e^{Y_{\text{mag}}})\cdot(\tilde{M}_{\text{mag}}\cdot e^{\tilde{M}_{\text{phase}}})=Y\cdot\tilde{M}\] \[=(Y_r+jY_i)\cdot(\tilde{M}_r+j\tilde{M}_i)\] \[=(Y_r\cdot\tilde{M}_r-Y_i\cdot\tilde{M}_i)+j(Y_r\cdot\tilde{M}_i+Y_i\cdot\tilde{M}_r) : \text{DCCRN-C}\]DCCRN-C와 DCCRN-E의 차이점은 DCCRN-E가 \(\text{arctan}\)라는 activation function을 추가적으로 사용한다는 점이다. Complex ratio mask(CRM)는 아래와 같은데 DCCRN-C와 DCCRN-E가 CRM을 target으로 한다는 점도 대입을 통해 쉽게 알 수 있다.
\[\text{CRM}=\tilde{M}=\frac{Y_rS_r+Y_iS_i}{Y_r^2+Y_i^2}+j\frac{Y_rS_i-Y_iS_r}{Y_r^2+Y_i^2}\] \[\tilde{M}_r=\frac{Y_rS_r+Y_iS_i}{Y_r^2+Y_i^2},~~~\tilde{M}_i=\frac{Y_rS_i-Y_iS_r}{Y_r^2+Y_i^2}\] \[\text{DCCRN-C}: \tilde{S}=(Y_r\cdot\tilde{M}_r-Y_i\cdot\tilde{M}_i)+j(Y_r\cdot\tilde{M}_i+Y_i\cdot\tilde{M}_r)\] \[=(Y_r\cdot\frac{Y_rS_r+Y_iS_i}{Y_r^2+Y_i^2}-Y_i\cdot\frac{Y_rS_i-Y_iS_r}{Y_r^2+Y_i^2})+j(Y_r\cdot\frac{Y_rS_i-Y_iS_r}{Y_r^2+Y_i^2}+Y_i\cdot\frac{Y_rS_r+Y_iS_i}{Y_r^2+Y_i^2})\] \[=(\frac{Y_r^2S_r+Y_rY_iS_i}{Y_r^2+Y_i^2}-\frac{Y_rY_iS_i-Y_i^2S_r}{Y_r^2+Y_i^2})+j(\frac{Y_r^2S_i-Y_rY_iS_r}{Y_r^2+Y_i^2}+\frac{Y_rY_iS_r+Y_i^2S_i}{Y_r^2+Y_i^2})\] \[=\frac{Y_r^2+Y_i^2}{Y_r^2+Y_i^2}\cdot S_r+j\frac{Y_r^2+Y_i^2}{Y_r^2+Y_i^2}S_i=S_r+jS_i\]DCCRN-CL은 DCCRN-E와 같은 target에 complex LSTM을 사용한 모델이다.
Leave a comment